買ってよかったもの2022
2022年4月3日に大学の寮に入居し、一人暮らし生活が始まった。そこから8ヶ月、なんだかんだ不満のない生活を送れているので、特に買ってよかったものをまとめて記録しておこうと思う。
引っ越して最初の1ヶ月はめちゃくちゃ物を買ったので、4月編・4月以外編の2部構成でいきます。
<4月編>
せっかくなので購入日の時系列で紹介します。引っ越し直後のライブ感を味わえるかも。
4/3
クリンスイ モノ

入居後、真っ先に買ったのがこの浄水器。そんなにスペースを取らないし、デザインもメタリックで周囲の邪魔をしないということでこれを選んだ。
出てくる水も結構美味しくて、一度こっちを飲んでしまうと元の水道水には戻れない(ペットボトルの水ほどではないが)。今でも僕の摂取する水分の過半数を担っており、かなり飲み物代を削ってくれていると思う。
Anker ケーブルホルダー
")
ガッッッチで役に立った。机が結構狭いので、これを机横のポール(金属製)にくっつけてケーブルを浮かせて収納している。ホルダー自体の収納効果だけではなく、ケーブルに定位置が存在することで机が散らからなくなるのが隠れたメリット。
Switchbot スマートカーテン

最高!!!!!ちょっと値が張る(約8000円)だが、「朝晩カーテンを開け閉めする」という意味の分からない家事から開放されるのが素晴らしい。
毎朝8時にカーテンが自動で開いてくれるので、実家にいた頃よりだいぶ朝起きられるようになった気がする。
4/5
AndroidをMagsafe対応にするやつ(ESR HaloLock)

充電周りの環境を整備しようと思って、Galaxy S21(のケース)に装着するために購入した。このリングは本来iPhoneのケース越しでもMagsafeにくっつくようにするためのものだが、Galaxyもオフィシャルにサポートしている。専用のアダプターがついていて、簡単に位置合わせ・貼り付けができた。
ただし、真価を発揮するのはこの数カ月後に購入するモバイルバッテリー・スマホリングと組み合わせるようになってから。
4/8

寮はキッチンが信じられないほど狭い。Youtubeで「うちよりキッチン狭い部屋あるん?」という動画があったが、そこより狭かった。 自炊しようとするとIHヒーターの上のスペースをまな板として使いたくなったので、スープやカレーを簡単に作るべくこれを購入。
買って使ってみた結果、お米が美味しく簡単に炊けるのが想定外のメリットだった。内蔵のお米モードではなく、手動で圧力4分に設定して作ると1時間くらいで炊けてうまい。セールとかポイントとかをうまく使うと10000円前後で購入できるわけで、炊飯器の完全上位互換だと思ってるんですけどどうですか?
4/9
Baseus ACアダプター&延長コード
 採用 多機能 USB-C充電器【2*USB-C 2*USB-A 2*ACコンセント / AC・DC独自冷却システム搭載 / ほこり防止シャッター / アース付き / 1.5mコード】 OAタップ MacBook iPhone iPad Galaxy S22 Ultra Android 各種 TypeC機器対応 同時充電 100WのUSBケーブル付き PSE技術基準適合 PowerCombo (ブラック)")
コンセントまで長いケーブルが伸びているタイプのACアダプター。合計4ポートあるので、USB-Cx2, MicroUSB, スマートウォッチのケーブルを常に挿しっぱなしにしている。合計65WでスマホやPCの充電も余裕。
これを買うまでは充電する機器が変わるたびにケーブルを刺し直していたが、この差し替えの手間が軽減されるのがマジで快感。挿しっぱなしのケーブルをAnkerのケーブルホルダーでまとめれば、デスク上の配線が一撃できれいになる!
1250Wまでの延長コードも兼ねているので、電気圧力鍋(800W)に電力を供給する役割も兼ねている。かなり無理させている気はするが、全く熱くなる気配がないのが凄い。アースもあるし。
タオル研究所のフェイスタオル
![【Amazon.co.jp限定】タオル研究所 [ボリュームリッチ] #003 フェイスタオル ライトグレー 5枚セット ホテル仕様 ふかふか 高速吸水 綿100% 耐久性 毛羽落ち少ない 【選べる10色】 Japan Technology](https://m.media-amazon.com/images/I/51zq5a8SQoL._SL500_.jpg "【Amazon.co.jp限定】タオル研究所 [ボリュームリッチ] #003 フェイスタオル ライトグレー 5枚セット ホテル仕様 ふかふか 高速吸水 綿100% 耐久性 毛羽落ち少ない 【選べる10色】 Japan Technology")
あらゆるYoutuberがオススメしている、無難なフェイスタオル。若干大きめ・ぶ厚めなので僕はバスタオル代わりに使っている。 バスタオル・フェイスタオルの2種類を収納できるだけのスペースを確保したくなかったので……。
フェイスタオルの相場って全然知らないんだけど、この品質で5枚で1800円はめっちゃくちゃ安いと思う。おすすめされる訳もわかる。
4/10
Xiaomi ハンディクリーナー

Xiaomiがセールをやっていて、2000円くらいで売っていたので即購入。Ankerの同様の商品だと5000円くらいしたのでとてもお得に買えた。
部屋の掃除はクイックルワイパーでやっているからフルサイズの掃除機を買うつもりはなくて、オートミールやプロテインをこぼしたりとちょっとした汚れを吸い取るのに使っている。持ってないと必要性が分かりづらいが、あったらあったでめっちゃ便利!
4/11
プラス キッチンばさみ

電気圧力鍋が届いたが、包丁がなかった。いい感じの包丁を調べるのに時間がかかったので、とりあえず簡単な料理をするためにキッチンバサミを購入。実家でも使っているものなので信用があった。
今でも牛乳パックを切ったり、ウインナーや野菜、鶏肉を切るのにまな板出したくないなぁみたいな時に八面六臂の大活躍をしている。
4/12
下村工業の包丁

いい感じの包丁を調べたところ、予算と求める品質がマッチしていそうなのがコレだった。
セラミック包丁も人気だが、先端が欠けることがあるらしい。中学時代には「クラッシャー」というあだ名が着くくらいモノを壊しやすいので、普通に使ってたら壊れようがない金属製を購入。
今のところ研ぎ直す必要もなく快適に使えているので、いい買い物だったなと思っている。まあまあ安かったし。
<4月以外編>
 - シルバー")
手汗が出やすい体質で、ルーズリーフに手書きするのがどうしても苦手だったのでデジタルノートを取りたかった。卒論にも使えそうだしということで一念発起して購入。動画を見たり作業したりで色々役に立っている。
家電量販店やネット販売だと納期が1ヶ月くらいかかるっぽくて、色々探したら大学の生協で現物が一点だけ残ってたので当日にお持ち帰りできた。嬉し
セイコーの置き時計

6月に購入するまで部屋に時計がなかったので、古いiPadをつけっぱなしにして時刻を表示してやりくりしていた。マジで?
スマホやPCで時間はわかるとはいえ、時計があるとすぐに時間がわかるので便利(自明)。温度とか湿度がわかるのもありがたいので持っとくと吉
レック ハンディクリーナー
 スゴ技カット カーペットクリーナー")
要は布団や枕に使えるコロコロ。アレルギー体質なので、この辺の掃除にはできるだけ気を配っている。自立するので置き場所に困らないのがけっこう助かるポイント。
WINZONE プロテイン(サワーストロベリー風味)
ホエイ プロテイン パーフェクトチョイス 1kg サワーストロベリー風味 国内製造 11種ビタミン 4種ミネラル whey protein 100 国際味覚認証受賞")
運動はあまりしないが、朝食やおやつ、夜食の代わりにプロテインを飲むことがある。今まではザバスを使っていたが、安かったのでこれを購入。牛乳で溶かすといっぱしのスイーツくらい甘くて美味しい!ただ運動後だとくどいかも?
商品ページには水(or牛乳)が150mLと少なめで済んだり、シェイク1秒で溶けたりと良いことが書いてあるが、全部マジ。怖いくらい溶けやすいが、そのためか龍角散くらい粒子が細かくてその辺に飛び散るのが唯一の欠点。
HYPER ワイヤレスモバイルバッテリー

Magsafeのリングを取り付けたGalaxy S21で使っている。Amazonでよう知らんメーカーのものを買ったら異常発熱して怖かったので、昔から知名度のあるHYPERのものを量販店で買った。
ただ、ワイヤレス充電だと効率も充電速度も落ちるので、本体にマグネットでくっつけた状態で短いUSBケーブルをつないで充電することが多い。モバイルバッテリーを重ねて持つ手間がなくなるので、この形が個人的なベストかなと思ってる。
パナソニックのLEDランタン

見た目が面白くて冗談半分で買ったがめちゃくちゃ役に立っている。
夜寝るとき、天井の常夜灯だと明るすぎて眠れないが完全にオフにすると暗すぎて不安な自分にとって、少しだけ光ってくれる常夜灯として超優秀。
早押しボタンみたいに上から手のひらで叩くことでオン・オフを切り替えられるのが直感的で楽しい。あと上部を取り外すと懐中電灯にもなるということで、「防災グッズを持っているんだぞ」という気持ちにもなれて嬉しい。
Switchbot ハブミニ
")
スマートカーテンなどのSwitchbot製品をWifi経由でコントロールできるほか、これ自体にリモコン機能があるのでテレビやエアコンを操作できるようになるガジェット。
スマートカーテンを買った4ヶ月後に、エアコンを自動で操作したくて購入。実家からAmazon Echoを持ってきていたので、「エアコンを20℃にして」「エアコン消して」とかを寝ながら声で操作できるのが素晴らしい。
特に冬はエアコンの温度変えるために布団から出るのって面倒だからさッ……良いのよこれが……
コイズミのちいちゃいドライヤー

個人的今年の掘り出し物ランキング第一位。
レビュー数も多くなく、ランキングも上位ではないドライヤーだが、本体を短く・持ち手が折れる機能をオミットしたことで本体がめっちゃ小さくなった。
ノズルが短いので髪の長い女性には不向きというレビューがあったが、当然当方独居成人男性、全く問題なく使用できている。
安くて風量も強くてしっかり乾かせてコンパクトなので、ドライヤーを探している髪の短い方には特におすすめしたい。

生活リズムがブッ壊れてきたので、睡眠記録装置として購入。Amazonだと2万円を超えているが、Paypayモールでポイントとかセールとかを駆使して13000円前後で購入できた。
僕が必要だった機能は アラーム・睡眠ログ・カレンダー連携 の3つだけだったので、これで必要十分という感じ。お目当ての睡眠記録機能も予想以上で、睡眠時間とパフォーマンスの相関みたいなのが実感できるから夜更かしを避けようというモチベーションが生まれた。
常に身近にあるタイマーとしても優秀で、洗濯機を回したときに終了までのタイマーをかけるようにしてから取り忘れが劇的に減った。
操作の滑らかさや睡眠・心拍の記録精度なんかを考えると、スマートウォッチを買うなら最低10000円は出したほうが後悔しないかなって感じがある。Amazfit GTS 4 miniなんかもおすすめ。(両方買った)(なんで?)
ERASE タオルハンカチ

手汗が出やすい体質なので、ハンカチよりも気軽に手を拭けるハンドタオル派。5枚1000円だし失敗しても良いやという気分で買ったら意外とよかった。
レンジピヨ 3エッグ

レンジで作るゆで卵機。名前可愛いかよ!上部のアルミ製の部屋に卵を入れて、下部のプラの部分に水を入れることで、レンチン7分+待機7分でおいしいゆで卵が作れる。栄養バランスがおかしくなりがちの一人暮らしで、ゆで卵のような栄養価の高いものを食べるハードルを下げることは大切だなと実感した。
Recopo(レンジ鍋)
 らくチン 便利 レンジ鍋 Recopo NIM-118-BL")
野菜と鶏肉と鍋キューブと水を入れてレンチン12分で鍋ができる、神のアイテム。100均にも似たようなものがあるが、そちらと比べると明らかにビルドクオリティが高く、安心して食器として使えるのでこっちを買うほうが良い。
最近は寒くなってきたので、もやし・白菜・シメジ・鶏ももで胡麻坦々鍋を作り、〆に冷凍うどんをチンしてぶち込むのがルーティンになっている。こんなに具だくさんなのに洗い物1個で済むのが何より最高!!!
CIO USBポート付き延長ケーブル

枕元にもUSBポートを用意しておきたかったが、配線がゴチャつくのも避けたかったのでこれを買った。他の類似商品より出力がデカいので、USB-AポートでSwitchbot ハブミニに常時給電しながらUSB-Cポートからスマホを急速充電できる。
まだ活躍の機会はないが、旅行に持っていくのもよさそう。
カロリーメイト バニラ味 30個入

ここ最近、朝食をカロリーメイト+カフェオレに固定することに成功している。最大の成因はバニラ味が出たこと。めっちゃ美味しくて何日連続でも食べられる(主観)。
30箱で5000円なのでドラッグストアやスーパーで買うのと単価は大差ないが、手が届く場所に必ずカロリーメイトが存在するという状況が安心材料になる。
パール金属 食器 水切り かご バスケット 2段 ダークグレー 珪藻土トレー付

キッチン狭い仲間にぜひ買ってほしい代物。普通の水切りラックは底部にドレーンがついていて水がコンロに流れるようになっているため、コンロのそばに置く必要がある。
ところがこれは食器の水を珪藻土がすべて吸ってくれるので、部屋のどこに水切りラックを置いてもいい!!これがどれだけ素晴らしいことかは、食器の収納場所に一度でも悩まされたことがあればわかってくれるはずだ。
これを導入してから自炊の頻度が一気に増えたばかりか、プロテインシェーカーや水筒を洗って干しておくのが簡単になったので水やプロテインをたくさん飲めるようになり、健康が増進され、睡眠時間が長く取れるようになり、精神が安定し、卒論が終わり、彼女ができた。
あっ
卒論は終わってないし彼女もいないです さようなら メリークリスマス
【徹底比較】Pixel Buds Pro VS Nothing Ear(1) VS 安部菜々
勢い余って2つもイヤホンを買ってしまった。
そこで、
- Pixel buds Pro (Google)
- Ear(1) (Nothing)
- 安部菜々 (アイドルマスター シンデレラガールズ)
のそれぞれについて、以前から使用していたSONY WF-1000XM3とも比較しながら、様々な観点から比べていきたいと思う。全体的に(音質などの部分は特に)主観の部分が多々入るので、そこはご容赦ください。
価格(税込)
Pixel Buds Pro : 23,800円
Nothing Ear(1): 12,650円
安部菜々 : 無料(無課金の場合)
WF-1000XM3 :14,980円(2022/08現在)
Pixel Buds Proは、すべての完全ワイヤレスイヤホンの中でもハイエンド機の部類に入る価格だ。数年前にWF-1000XM3を購入したときもPaypayの20%キャンペーン込みで約20000円ちょうどだったので、価格帯としてはほぼ同じくらいと言ってよいだろう。
Nothing Ear(1)は、いわゆる「全部入り」イヤホンにしては実はかなり安い部類に入る。カタログスペックだけ見比べれば、Pixel Buds ProがNothing Ear(1)に勝っている部分はマルチポイントだけしかない。
この項目では各イヤホンの機能の良し悪しについては触れないが、Airpods Proと同じような機能を体験してみたい!というのが目的であれば、Nothing Ear(1)のコスパはかなり高いといえるだろう。
一方で、安部菜々は『アイドルマスターシンデレラガールズ スターライトステージ』をインストールしていれば無料で入手することができる。ガチャさえ当てれば一切お金を支払わずに入手することができるため、安部菜々のコスパは4種類の中で最も高い。
WF-1000XM3も、時が経って値崩れしているのでお買い得。僕は本体が大きくてしょっちゅう耳が痛くなっていたので買い替えたが、そうした装着感や非防水の点が気にならなければ充分「イケる」イヤホンだと思う。
価格の評価:Pixel Buds Pro<<WF-1000XM3<Nothing Ear(1)<<<<<安部菜々
見た目
Pixel Buds Pro

これ、僕はかなり好き。この画像からは伝わりづらいけれど、ケース全体が梨地っぽいサラサラの手触りで、プラスチッキーなのに高級感がある。開く部分に引かれた黒いラインもおしゃれで、PortalみたいなSFゲームに出てきそうな見た目って感じ。
Nothing Ear(1)>
かっこいい~~~~!!!これはAmazonの商品画像だけど、マジでこの画像の通りのものが届く。特にケースはずっと見ていられるようなデザインをしている。フタがスケルトンということで、ケースを開く場所によって表情を変えるのがまたオシャレ。街中でふと開いてみたくなるような感じがする。「所有欲を満たされる」という軸でこれ以上強いイヤホンはないだろうと思う。

安部菜々

かわいっ かわいすぎ罪?
デレステのサービス開始の頃から約6年半眺めているけれど、全く見飽きる気配がない。むしろ見るたびに好きになる。2Dでも3Dでもフィギュアでも安定してかわいいのは、安部菜々が「かわいい」を突き詰めたコンセプトだからなのではないかと思う。見ようによってはアホの子にも見える彼女に、底しれぬ意志とスター性をも与えているのは紛れもなく下瞼に見える頬の若干の膨らみだと思うんだけど……どう?例えばこのカードとか…

え?やば……… ケコーン
WF-1000XM3


ケースは黒と金でどっしり構えた感じのデザイン。かなり高級感があるので、こっちも所有欲を満たしてくれる。ただ実際触ってみると、メタリックなフタ部分が想像よりプラスチッキーで少しガッカリするかも。まあ実際に金属で作られても重いし困るんだけど。
他とは別軸のゴツくてかっこいいデザインという印象で、この路線で最近発売されたものだとテクニクスのEAH-AZ60が近いだろうか。
ただしケースが城くらいデカい上に銀河系くらい分厚いので、カバンの中でかなり場所を取る。間違いなくポケットには入らない。この点をどう評価するかは、人によって異なってくるところだろう。
見た目の評価:WF-1000XM3<=Pixel Buds Pro<<Nothing Ear(1)<<<<<越えられない壁<<<<<安部菜々
音質
※音楽経験はろくにないし、1万円以上の有線イヤホンを買ったことがないようなイヤホン素人なので、音質評価はそんなに当てにしないでください
Pixel Buds Pro
1日聞いた限りだと、低音が強いように感じた。ただ、安めのイヤホン特有の「鳴らせば良いんだろ!?」的な機械で増やしたような低音ではなく、しっかりキレイに鳴っている感じがする。解像度や分離感もいい感じ。
ドンシャリってほど高音が強くはない……ような気がする。全体的に、ボーカルがちょっと遠くてベースラインがしっかり聞こえるようなイヤホンなのかなという印象。
小音量時に低音と高音を増やしてくれるボリュームEQという機能が面白い。普段より小さい音量でも音楽を楽しめる、気がする。
イコライザーが秋に実装予定らしいので、それを楽しみに待ちたい。
Nothing Ear(1)
まあ予想はしていたけれど、音質に振っているイヤホンではないよね、という感じ。ただ音が悪いということは決してない!……と思う。低音がちょっと足りないような気もするけれど、高音やボーカルはしっかり聞こえている。
「デザインにこだわったから他の機能や音質は疎かなんでしょ?」と思っているなら、そんなことはないぞと胸を張って言える。そんな音質だと思います。
声を聴くたびに、声優の三宅麻理恵さんがまさに「ハマり役」だなと痛感する。三宅麻理恵さんはもともと赤城みりあ(11歳)役でオーディションを受けていたらしいが、その演技での「キツさ」を見抜いたスタッフの方が安部菜々役として大抜擢したという噂を聞く。
安部菜々がギャグっぽい役回りも、アイドルらしい凛々しい役割もできるのは三宅麻理恵さんの持つ天性の才能によるものなのだろうと思う。
ソロ曲の「メルヘン∞メタモルフォーゼ!」は、アニメの声優を目指す安部菜々の夢が叶い、自らを主役とするアニメの主題歌を歌えたというような設定の曲。「ウサミン」と「安部菜々」が入り交じる渾身の歌声は鼓膜から脳に素早くはたらき、聞くたびに涙が出る。
「メルヘン∞メタモルフォーゼ!」のハイレゾ音源ももちろん購入したが、ここで挙げたワイヤレスイヤホンはハイレゾを再生できない。正直サブスクばっか聞いてる僕の耳でそこまで大きな差を実感することはあんまりないが、推しのハイレゾ曲が聞きたいという方は、LDACやAptx HD/Adaptive , Samsung Scalable Codecなどのハイレゾコーデックに対応したイヤホンを購入するのも良いかもしれない。
WF-1000XM3
ソニーのハイエンドってやっぱりすごい。マジで他のイヤホンと格が違う。僕はもうこれ以上の音は望まないかな~って感じ。
イコライザー次第で、低音重視にも高音重視にもバランス型にもなる。地力があればどの役割でもやれてしまうんだな~と思うので、音質にそこまで拘る人じゃなければこれ1本で大抵の人の好みは満たせるんじゃないかな。
レビューを見ると「低音が足りない」と言っている人がちらほらいるけれど、たしかにドンシャリ傾向ではない上に、おそらくはイヤーピースが合ってないんじゃないかなと思う。
正直、付属のイヤーピース(耳に入るゴムみたいな部分)はあんまり良くない。自分に合うものを見つけて、しっかりフイットさせた途端にこのイヤホンは化ける。
僕はFinal Eタイプ 完全ワイヤレス用のSサイズに落ち着いた。このイヤーピース、かなりいいのでぜひ。
音質の評価:Nothing Ear(1)<<Pixel Buds Pro<<<安部菜々<WF-1000XM3
装着感
Pixel Buds Pro
装着感はかなり良い。ハイエンド機では群を抜いて小型なのがPixel Buds Proの強みの一つだろう。
いわゆる「そら豆」的な小さい本体にイヤーピースが斜めに生えているつくりなので、耳への収まりはめちゃくちゃ良い。
右耳がかなり小さくて大抵のイヤホンは入らない自分でも、長時間つけても少し耳が痛くなる程度で済んだ。(これのせいで、WF-1000XM4が耳に入らなくて購入を諦めた)
Nothing Ear(1)
こちらも装着感が素晴らしい。外側はとても独創的なスケルトンの見た目だが、実は裏面はAirpods Proにきわめて似ている。つまり、Airpods Proが合う人は合うし、合わない人は合わない。僕は合うタイプだった。
耳の奥までイヤーピースを突っ込むタイプではないので、装着の負担はものすごく小さい。
安部菜々
安部菜々の装着感!?!?安部菜々を装着って………何!?何考えてるんですか!?!?破廉恥!!!!!!!
WF-1000XM3
筐体はほかと比べてバカでかいが、イヤーピースがしっかり合えば意外と負担にならない。とはいっても決して装着感が良くはないし、長時間つけているとさすがに耳が痛くなるが。
兎にも角にも、自分にあったイヤーピースを見つけられるかどうかが装着感を分ける。面倒だからといって付属のやつだけを使っていると地獄を見る場合があるぞ!
装着感の評価:安部菜々<<<WF-1000XM3<<<Pixel Buds Pro<Nothing Ear(1)
ノイキャン
Pixel Buds Pro
かなり強いほうだと思う。電車やスーパー、混んだファミレスやデカい換気扇の音もしっかりかき消してくれる。ただし、耳にイヤーピースを突っ込まない構造上どうしても中音域以上、特に人の声が完全には消えきれてくれない印象がある。
ノイキャンの強さ以外の特筆すべき点は、耳の中の圧迫感がやたら少ないというところ。ふつうノイキャン起動時には耳に指を突っ込まれるような圧迫感があって、その圧迫感はノイキャンの強さに比例するはずなのだが、Pixel Buds Proはその比例関係を無視している。
おそらくはPixel Buds Proに搭載された減圧機能が関係しているのだとは思うが、減圧機能に言及した記事がぜ~んぜんないので詳細は一切不明。
Nothing Ear(1)
街を散歩したり、屋内で使うなら全然アリ。ファンの音や車数台のエンジン音ならバッチリ消える。
ただ、電車やスーパーなどデカ目の音には負けてしまうかなという感じ。あと、Pixel Buds Pro同様に人の声が苦手気味。低い「ゴーッ」という音はすこぶる無音になるので、ストレスは大幅に軽減してくれる。
安部菜々
見ているだけで周囲のノイズを低減する作用がある。また、電車のノイズにも強い。Bluetoothを切ったまま電車内でデレステを起動して、安部菜々の声でタイトルコールが「アイドルマスター!シンデレラガールズ!!」と鳴り響いたときには、それはもう背筋は凍るしよく聞こえる。
WF-1000XM3
なんだかんだ非常に強い。後継機のWF-1000XM4は耳に入らなかったのでノイキャンを体験できていないが、電気屋で他機種をちらほら試聴した限りでは現存する全イヤホンの中でもトップクラスに強いのではないだろうか。やはり耳奥に突っ込むタイプなので、いわゆるパッシブノイズキャンセリング(=イヤホンの耳栓としての機能)が強く働いている。
ただ当然圧迫感も強いので、この点はPixel Buds Proに劣るかなあといったところ。
またイヤーピースの話になるが、ここもイヤピ選びでノイキャンの品質が大きく変わる。Amazonの「ノイキャンが全然効いてない」という低評価レビューは、9割がた初期のイヤーピースをそのまま使っているのが原因だと勝手に推測している。このイヤホンを買ったら、まず最初にイヤピ選び。これ約束です。
ノイキャンの評価:Nothing Ear(1)<<<安部菜々<Pixel Buds Pro≒WF-1000XM3
外音取り込み
Pixel Buds Pro : ちょっと良い
Nothing Ear(1): エンジン音を増幅しちゃって声が聞きづらい
安部菜々 : 非対応
WF-1000XM3 :普通(値段よりは良くないかも)
僕が外音取り込みを殆ど使わないのもあるが、何よりAirpods Proにはいずれも遠く及ばないという印象がある。強いて言えば、人の声を聞くならPixel Buds Pro、散歩中に車のエンジン音に気づく目的ならNothing Ear(1)が良い。
WF-1000XM3はモード切替ができて、普通の外音取り込みモードと人の声に気づきやすいモードを切り替えられる。用途に合わせて設定しよう。
外音取り込みの評価:Nothing Ear(1)<<<安部菜々<Pixel Buds Pro≒WF-1000XM3
操作性・取り回し
Pixel Buds Pro
操作感はかなり良い。センサー部分がなんかサラサラしているのと、タップ・スワイプの反応がとてもキビキビしている。
ただし、耳から出ている部分の全面がタッチセンサーなので、人によっては誤操作が多いかも。
個人的に素晴らしいと思ったのは、ノイキャン/外音取り込み/オフの切り替えをカスタマイズできること。
つまり、普通のイヤホンみたいに3種類をローテーションさせることもできるし、Airpods Proみたいにノイキャン⇔外音取り込みの切り替え式にもできるし、外音取り込みを使わない場合は ノイキャンON⇔ノイキャンOFF を切り替えるだけにできる!!!!!
WF-1000XM3を使用していた際にノイキャンを消すのに外音取り込みをいちいち経由して2回タップしないといけないのがずっとしんどかったので、この設定ができるというのがPixel Buds Proを買った最大の理由。
さらに、マルチポイントも超すごい。PCやiPadで動画を見ていたところからスマホの音楽に切り替えたければ、イヤホンをタップして停止して、スマホから再生するだけでいい。魔法?
マルチポイントは「スマホ+何か」という形が基本になるが、この「何か」の部分の切り替えもめちゃくちゃ早い。iPadとパソコンを登録しているが、おそらくは近いほうが自動で選ばれている。いやだからこれ魔法?
Nothing Ear(1)
こちらも操作感は良い。ただ少しスワイプの反応に難があるかも。
いわゆる「うどんの部分」の表面でタッチを受け付けるので、ズレたイヤホンを直すときはうどんの側面を持つようにすれば誤反応もない。
また、接続の「上書き」ができるのもありがたい点。古いデバイスから切断の操作をしなくても、新しいデバイスの方から接続操作をすれば勝手に古い方との接続を切ってくれる。
ここに言及しているのは僕を除くとGIZMODOの網藤さんしかいない気がするが、僕にとっては絶対に外せない機能だ。
安部菜々
マイページで安部菜々をタップすると、そのときどきで違う台詞を喋ってくれる。とても操作性に優れているといえるだろう。あとかわいい。
WF-1000XM3
タッチセンサー式なので完全ワイヤレス物理ボタン原理主義者は買う気をなくすかもしれないが、タッチセンサーの機種の中ではとても使いやすい部類だと思う。というのも、筐体がデカすぎるゆえにタッチセンサーの反応部分が中央の丸い部分だけになっていて、その他の部分を持てば誤爆の心配がないから。デカさもたまにはプラスに作用するのだ。
こちらも接続の「上書き」に対応している。ただ、いわゆるフラッグシップ機の値段であればマルチポイントが欲しかったという気持ちもなくはない。
後継機のWF-1000XM4もマルチポイントに対応していないらしいので、ソニーはマルチポイントに対応するつもりはないのかもしれない。
欠点はタッチのレスポンスが少し遅いところか。また非防水なので、雨の日に使いづらい点もネック。
操作性・取り回しの評価:WF-1000XM3<<安部菜々<<Nothing Ear(1)≒Pixel Buds Pro
まとめ
というわけで、様々な観点から四者を比較してみた。完全上位互換・下位互換といったものはなく、まさに一長一短といったところなのがわかる。
イヤホンを買うときは、予算と相談しながら「自分が妥協できる機能はどこか?」「絶対に譲れない機能は何?」と考えるのがおすすめ。
僕は外音取り込みと音質はある程度妥協できて、接続の上書きと装着感は絶対に譲れなかったのでNothing Ear(1)とPixel Buds Proに行き着いた。
これはあくまで一個人の考えなので、ぜひたくさんのイヤホンを家電量販店などで試聴して、良い買い物をしてほしい。
ウミガメのスープはランダム生成してもそれなりに遊べることがわかりました
「ウミガメのスープ」が今、楽しい。
面白みのないストーリーで、どこにでもいるような魅力の薄い登場人物が、普段誰もが過ごしているような日常を送るだけの、無名の小説家による小説。
そんな何の変哲もない小説が、何の変哲もないために売れまくっているという。
どういうことだろう?*1
こういった一見説明のつかない状況に対して、プレイヤーははい/いいえで答えられる質問を投げかけ、出題者がそれに答える。この質疑応答を繰り返して、真相に近づいていくゲームだ。
たとえばこの問題なら、
Q.日記や自伝小説のようなジャンルですか?
→いいえ!
Q.現代日本の話ですか?
→はい!
Q.買っている人達は、読む用途が目的で買っているのですか?
→はい!
Q.結果、無名な小説家は儲かりましたか?
→いいえ!
Q.その小説家は、死後に評価されましたか?
→はい!
Q.小説を買っている人々にとって、小説の内容はなんの変哲もない日常ですか?
→はい!
Q.未来予知が関係しますか?
→はい!
…このように、つながりがあるように見えない2つのできごとを推理を使ってつなげていく。これが「ウミガメのスープ」の基本的なルールだ。
今の問題であれば、隠されていた真実は
「過去に出版されたSF小説が、なんの変哲もないと感じるほどに正確に現代の生活を描いていたため、予言の書として有名になった」というもの。この答えを見てから問題を見直すと、問題が全く違って見えてくるのではないだろうか。
こういうゲームは「水平思考ゲーム」とも呼ばれている(こっちの名前のほうが有名かもしれない)。買い切りのゲームやサイトもあるにはあるが、誰も知らない問題を探してくるのは結構な手間だ。
頭を使うゲームが好きなので、僕は考えた末、こう思った。
「 ウミガメのスープ、もっとやりて~~~~~~~」
と。
そして、問題をその場で作ってその場で解けばいいのでは????という発想に至った。いわば「無限スープ」である。
<無限スープの作り方>
ふたりが問題文の前半と後半をそれぞれ同時に発表する普通のウミガメのスープと同じように進行されるが、
質問のたびにダイスを振り
偶数→YES
奇数→NO
とし、最終解答もこのルールにしたがう
たとえば、
前半「男が忘れ物をした。」
後半「翌日、世界の株価が暴落した。」
になったなら、
「男は忘れ物をした。翌日、世界の株価が暴落した。何故だろうか。」という問題が完成する。
その場で適当に考えた例なのに、なんとなく正解がありそうな感じを察してもらえるだろうか。
脈絡がないのがウミガメのスープの問題文の特徴なので、適当に文章をつないだら逆にそれっぽく見えちゃうし、なんか挑戦したくなるような雰囲気が出る。
この手法なら、ウミガメのスープを無限に作り出すことができる!スープが無限なのはこれを除くとガストのドリンクバーの横にあるたまごスープしかないので非常に貴重だ。
さて、ランダムに作った問題文に答えなどあるはずもないので、出題者の役割はサイコロに担ってもらうことにした。質問をしたらふつうの6面ダイスを1個振って、偶数なら「はい」奇数なら「いいえ」にしよう。ウミガメ好きたちの頭脳をもってすれば、正解がなくてもなんとなく合ってそうな答えに辿り着けるだろう。多分。
最終回答の判定もダイスに任せることにした。こっちもサイコロを振って偶数なら正解。奇数が出ちゃったら間違いなので、別の答えを考えなければいけない。
適当に答えを言いまくれば当たっちゃう脆弱性はあるけど、そこは雰囲気でなんとかする所存です。
さっそく、友人たち(


 )
)
を集め、自分( )
)
を加えた5人で
試しに遊んでみることにした。改めて、ルールは以下の通り。
①ふたりが問題文の前半と後半をそれぞれ同時に発表する
②「ウミガメのスープ」同様、Yes/Noで答えられる質問をする③サイコロを振って、偶数なら「はい」奇数なら「いいえ」が答えになる
④そして②と③を繰り返し、正解っぽいストーリーができたら最終回答をする
⑤またサイコロを振って、偶数なら正解!奇数なら間違いとなり②に戻る
最初の問題文は、前半を![]() 、後半を
、後半を![]() が担当することになった。
が担当することになった。
問題準備お願いします!せーのっ
前半:「大雨が急に降った」
後半:「桶屋が儲かった」
→「大雨が急に降った。その結果、桶屋が儲かった。どういうことだろう?」
えっちゃんとウミガメのスープしてるじゃん!
桶屋がどうして儲かったのかを突き止めたいね
Q.桶屋が儲かったのは、桶がたくさん売れたからですか?
 コロコロ…「いいえ!」
コロコロ…「いいえ!」
桶が売れた以外の理由で儲かったんだ
Q.桶屋は2019年現在生存していますか?
コロコロ…「いいえ!」
なんとなく江戸時代っぽいよね
確かに、現代で桶屋って聞いたことないし
Q.桶屋は犯罪に手を染めていましたか?
コロコロ…「はい!」
Q.桶屋は大雨の影響で犯罪を実行しましたか?
コロコロ…「はい!」
なるほど、大雨のおかげで犯罪に成功して儲かったってことだ
大筋が見えてきたし、犯罪の種類を細かく調べていこうかな
Q.桶屋は人を殺しましたか?
コロコロ…「はい!」
Q.桶屋は犯罪を日常的に行っていましたか?
コロコロ…「はい!」
Q.桶屋は世のために犯罪を犯しましたか?
コロコロ…「いいえ!」
Q.桶屋は殺人のために儲けを得ましたか?
コロコロ…「はい!」
Q.桶屋は金を渡されて殺人を請け負いましたか?
コロコロ…「はい!」
桶屋は殺し屋もやってるってことか!これは大ヒントだぞ
適当にダイス振ってるだけなのに完全にウミガメやってる気分になってきちゃった
殺し屋ですかって質問して確かめとく?
やめとこう、万が一いいえが出たら完全に詰むから
…「無限スープ」はこんな感じで進んでいく。
今の所の情報は、
・桶屋は殺人を金で請け負った
・大雨が降った影響で、桶屋は人を殺した
・世のために行った殺人ではない
万が一回答が矛盾しようものなら完全に”終わる”ので、微妙に注意を払いながら質問をつづけていく。
Q.桶屋はやむを得ず犯罪を起こしていましたか?
→いいえ!
Q.大雨が降ったことが桶屋の殺人の動機になりましたか?
→はい!
Q.桶屋に殺人を依頼したのは被害者自身ですか?
→はい!
え!?
は!?
被害者自身が殺人を依頼した!?
被害者が雨のせいで大損をして、その結果殺人を依頼したってことかな?
なるほど、それなら被害者は雨に関係ありそうな職業だ
適当にサイコロで答え決めてるとは思えない急展開ぶりに驚きを隠せない…
Q.被害者は花火職人でしたか?
→いいえ!
Q.被害者は漁師でしたか?
→はい!
大雨が降って、漁師が自分を殺させるほど苦しんだ、ということは…?
よし大体わかったぞ、最終回答します!
どうぞ!
A.「ある漁師の船が大雨のせいで沈没してしまった。仕事道具のすべてを失い生きる希望をなくした漁師は、自らに保険をかけたのち、残された僅かな財産を報酬にして事故死に見せかけた他殺を桶屋に依頼した」!
コロコロ…「はい!」
やったーーー!!
桶屋は裏稼業で殺し屋もやってたってことなんだな
適当に決めてるのにすごく納得しちゃった
「その目は…桶は桶でも、棺桶がほしいのかい?」ってね
え?
ランダムに持ち寄った文章とサイコロだけで、こんなにちゃんとした(?)ウミガメのスープができてしまった。
Q.「大雨が急に降った。その結果、桶屋が儲かった。どういうことだろう?」
A.ある漁師の船が大雨のせいで沈没してしまった。仕事道具のすべてを失い生きる希望をなくした漁師は、自らに保険をかけたのち、残された僅かな財産を報酬にして事故死に見せかけた他殺を桶屋に依頼した
「無限スープ」を使えば、サイコロやダイスアプリなどを使うだけで、誰でも簡単にしっかりしたウミガメのスープを遊ぶことができる。通話でもできるので、在宅の時間が増えた方もぜひ遊んでみてはいかがだろうか。
僕たちは楽しかったのでもう一戦やることにした。
問題文出そう!せーの
『除夜の鐘が鳴った』
『そして世界は音楽に満ちた』
→「除夜の鐘が鳴った。そして世界は音楽に満ちた。いったい何故だろうか?」
Q.大晦日のファンキー寺で除夜の鐘REMIX~ゆくBEATくるBEAT~が開催されましたか?
コロコロ…「はい!」
答え:大晦日のファンキー寺で除夜の鐘REMIX~ゆくBEATくるBEAT~が開催された
何???????
何???????
何????????????
<2021年5月 追記>
なんと、この無限スープ(無限ウミガメ)がアナログゲームになりました!!
『ドロッセルマイヤーさんのなぜなぜ?気分』というタイトルで、問題文の前半と後半がたくさん載った単語帳サイズのゲームです!
最初から問題文のパーツが準備されているので「お題を考えるのが苦手」という方でも楽しめますし、片方だけ自分でお題を考えるのも面白いと思います。リンク先のnoteから通販リンクに飛べたり、全国のボードゲームショップでも販売されているようなのでぜひ買ってみてください!
*1:出典元:「ウミガメのスープ 本家『ラテシン』」http://sui-hei.net/
問題制作:とかげ様
http://sui-hei.net/mondai/show/15428
【Powertoys】ミーティング参加時にZoomが繰り返し落ちる問題とその解決策【お前か】
結論
Powertoysで「ビデオ会議のミュート」をオフにしたら治った。

問題
今週火曜日から、デスクトップPCでZoomに入ろうとすると「Zoomが予期せず終了します」というダイアログが出てクラッシュ、その後も繰り返し強制終了するようになった。
手持ちのノートPC(Windows11)やAndroidスマホではこうした問題は出なかった。
環境
・OS: Windows 10 21H1
・GPU: GeForce RTX 3060Ti
・マイク: Blue Snowball iCE
・カメラ: なし
やったこと
・デバイスドライバーの更新
・Zoomのインストールフォルダの削除→再インストール
・Zoomのダウングレード(2021年5月のものに)
・再起動(無限回)
エラーが起こる条件
・Zoomへのサインイン後、ブラウザから戻るとき
・Zoomのアプリから設定画面を開くとき
・Zoom会議に入るとき(テストミーティングを含む)
→すべて「外部からZoomダイアログを開くとき」だな……
→グラボやCPUの問題ではなく、外部から強制終了されている?
解決
ハードウェアアクセラレーション的な設定の問題か?と思って変更しようにも、設定画面を開くとクラッシュするので何もできず。
「Zoom 起動しない」「Zoom crash」などで検索しまくっていたところ、
Zoom crash after 10 seconds - can't even log in - Zoom Community
というフォーラムにたどり着き、そこでPowertoys(Windows純正の便利ツール)に原因があるという記述を発見。Githubを調べると
PowerToys conflict with Zoom · Issue #14289 · microsoft/PowerToys · GitHub
というIssueがあり、ここのバグ報告を読む限り
「Powertoysの11月のアップデートで追加された ビデオ会議のミュート をオンにしていて、なおかつカメラを接続していない時に限りZoomが繰り返しクラッシュする」
とのこと。
治った
ということで、「ビデオ会議のミュート」を設定画面からオフにしたら治った。先週くらいにPowertoysを手動でアップデートした際にこの機能が追加されてしまったっぽい。
バグが無かったノートPCにもPowertoysは入れていた(し、更新もしていた)けど、Webカメラが内蔵されていたから問題なかったみたい。
その後Powertoysを最新版にアプデしたら、「ビデオ会議のミュート」をオンに戻してもZoomが落ちなくなった。
「台湾の白菜、向き揃いすぎ問題」を調べたら知らないことをひとつ学んだ

この白菜。「翠玉白菜」といって、宝石を白菜の形に彫った(なんで?)超貴重なものらしい(これ以上よく知らない)。展示されている台湾の故宮博物院ではお土産になるほど大人気の彫刻だ。具体的にどういうものか知らなくても、「台湾の白菜のやつ」くらいの解像度で知っている人は多いのではないだろうか。自分もそっちサイドの人間である。
友人に台湾旅行の際の写真を見せてもらったときにこの白菜の存在を久しぶりに思い出し、どんなものだったか調べてみると、とんでもない事実が発覚した。

白菜の向きが揃いも揃って同じすぎるのである。左下から右上に白菜が向かう形の画像が検索結果の大半を占めている。野球選手のプロフィール写真でも顔の角度にもっとバリエーションあるぞ。これはなにかの陰謀なのだろうか?
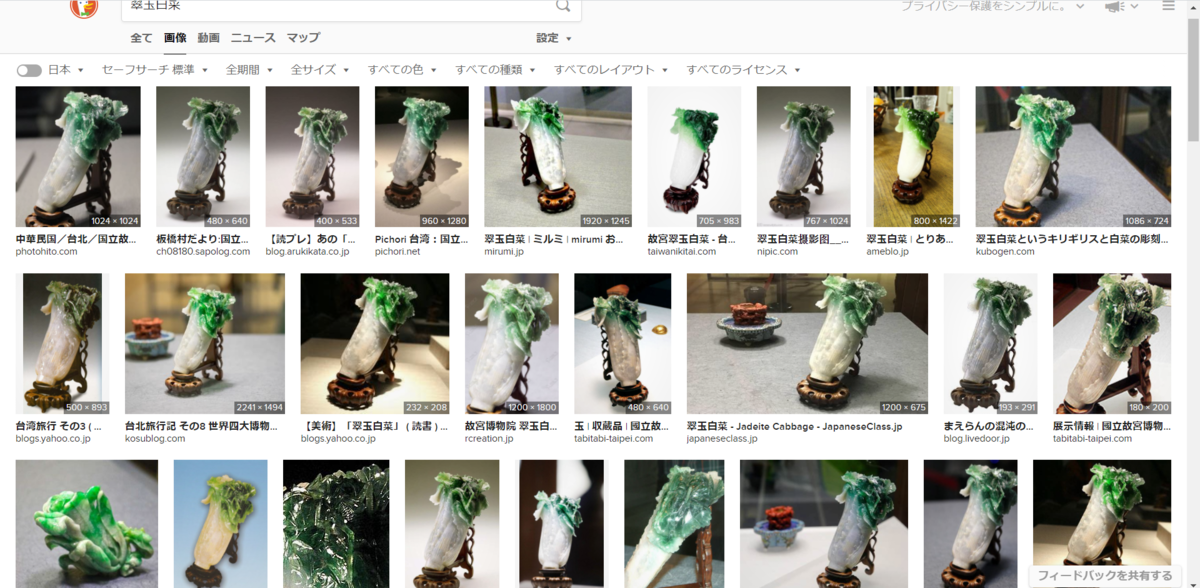
ダメだ……。なんと、正しいインターネットを提供しているはずのduckduckgoの検索結果ですら”例の角度”だらけだ。YoutubeやTwitterでも「翠玉白菜」と検索すると”この角度”の写真が大量に出てくる。調べてみてほしい。
一応、Googleとduckduckgoの検索結果の中にちらほら他の向きで撮影された写真が紛れ込んでいるので、この向きでしか撮影できないとか、そういうことはないはず。ではなぜ……?
Wikipediaを読んでみる。
翠玉白菜(すいぎょくはくさい、中国語: 翠玉白菜; 拼音: Cuìyù Báicài; 白話字: Chhùi-ge̍k Pe̍h-chhài)は、翠玉(翡翠)を[1]、虫がとまった白菜[2]の形に彫刻した高さ19センチメートルの美術品。現在は中華民国台北市の国立故宮博物院に収められ、同館を代表する名品の一つである[3]。
ん……?
翠玉白菜(すいぎょくはくさい、中国語: 翠玉白菜; 拼音: Cuìyù Báicài; 白話字: Chhùi-ge̍k Pe̍h-chhài)は、翠玉(翡翠)を[1]、虫がとまった白菜[2]の形に彫刻した高さ19センチメートルの美術品。現在は中華民国台北市の国立故宮博物院に収められ、同館を代表する名品の一つである[3]。
虫がとまった白菜……?ただの白菜と違うの……?

あ、右上のほうに結構なサイズの虫がいる!それでみんな虫を映すためにこの角度で撮ってたってことか。翠玉白菜の色は石が元々持っているもので塗ったりはしていないみたいだから、虫も白菜と同じ色になっちゃってたんだな。勉強になる。Googleの検索結果みたいな細かい疑問から全く新しいことを知ることができるんですね。
いや虫いるって知らんけど?!?!?!?!?!白菜の彫刻だと思うじゃん!!!?!?!?!?!?!?タイトルに虫って入れてよ!?!?!?!?!?!???!!!!!色同じだから写真だと注意して見ないと気づかないじゃん!!!!動画で見ろってか!?!?!?動画で見ろって!?!?!書を捨てて!?!?!?!?!?動画で!?!?!?!?
日本の教育は!!?!?!?!?それでいいんですか!?!?!?!?!?!?今こそ我々の手で冷凍みかんを解凍!!!!!!!!!冷凍!!!!!!!!!!解凍!!!!!!!!!!!!!冷凍!!!!!!!!!!!!!!
酵素がたくさん死んでらあな!!!!!!!!!!!!!!
割り箸の利便性に違和感がある
割り箸の利便性に違和感がある。
いやなにも、割り箸が不便だと言いたいわけではない。むしろ便利すぎるという話をしたい。保管性と携帯性が良すぎるという話を。
そもそも箸って「先端を汚しちゃいけない2本の棒」なわけで、本来丁寧に扱うべきな代物のはず。それが割り箸になったとたん猛烈に扱いが雑になって、袋にミチミチに詰まってバーベキューに持ち込まれたり、ケータリングの弁当箱に括られてたり、レジ袋の上の方に雑に放り込まれたりする。しかもそんな雑な扱いを受けていてもすぐに使える。
使い捨てだから便利だという側面はあるかもしれないが、それにしても割り箸は強すぎる。使い捨ての歯ブラシとか紙コップとか石鹸とか、そういうのと比較しても圧倒的に雑に使えるし便利な気がする。
他の使い捨て商品との違いといえば、割らないと使えないところくらいな気がするが……。「2つがくっついてる」だけでこんなに便利になることあるか?
割り箸とほかの使い捨て商品とを比較すると、割り箸の包装の単純さが際立つ。紙皿や紙コップのような使い捨て商品はたいてい使う直前にビニールの包装から1つずつ取り出さないといけないのに対し、割り箸は箸袋からサッと取り出すだけで使えるようになる。強すぎる。この違いはどこから来るのか?
自分なりの解釈として、「割り箸は未完成だから便利」という説を立ててみた。
すべての使い捨て商品には包装が必要だ。ビニールで包んだり、箱に入れたりする包装をすると、使用するために包装を開けるひと手間が必要になる。 この「開けるのに手間がかかること」は、包装という概念にとって重大な意味がある。開けるのに手間がかかるからこそ、商品は外界と遮断されていること(≒清潔であること)や、未使用であることが証明される。
そして「包装を開けること」は、開けた瞬間に初めて商品が使えるようになったことを意味する。ということは、包装は「完成した商品を意図的に未完成(完成一歩手前)に戻している」と言えるのではないだろうか?商品がビニールに包まれたり紙箱に入った状態ではまだ未完成で、それらを切ることではじめて紙コップやおしぼり等が「完成」するという考え方だ。封なんて開けなくても商品はとっくに完成しているが、使用者から見ればまだ「未完成」ということ。そして使用者がビニール袋を切って、未完成なものをその手で完成させる。これが「開封」だ。
で、割り箸の話。割り箸を使うときには、「自力で2つに割る」というプロセスが挟まる。この「割る」という行為がめちゃくちゃ強いのだ。
割り箸は2本の箸がくっついているという部分が、「完成した商品を意図的に未完成に戻す」という包装の本質に沿っている。つまり、割られてない状態の割り箸は「包装された状態」だと呼んでも良さそうだ。だが、この「包装」は他の包装と比べて根本的な部分に違いがある。この状態の箸は、本当に未完成なのだ。割り箸の製造工程についてはよく知らないけど、多分切り込みのいっぱい入った板を棒に切り分けるというのが最後のプロセスなんだと思う。その最後のプロセスを使用者に託すことで、「開封」と「製造」を同時に行わせている。無駄なことを一切していないのだ。完成している製品にパーツを追加してわざと未完成にする「包装」とは異なる。
割り箸は保管している時点では本当に未完成なので、箸が普段持っている「2本あるので扱いづらい」みたいな性質をもたない。割るまでは箸はどこにも存在せず、使用者が割ることで初めて、「開封」と同時に割り箸が完成し、さながら無からお箸が出現するかのような感覚で使用できる。
完成一歩手前の状態で直接提供しているから割り箸は便利だし(なんか激安スーパーみたいな表現だな)、他の2つ組の使い捨てのもの(ホテルのスリッパとか)はくっついていても大して便利にはならない。最後に2つに切るみたいな製造工程じゃないから。
割り箸に乾杯。
半蔵門線に乗った気になれるタイマーを作りました
電車に乗らなくなって久しい。大学の授業がオンラインだしバイトは地元だし、わざわざ東京まで足を運ぶこともなくなってしまった。
通学の時間がなくなるのは嬉しいが、そのぶん失われたものもある。 おととし、半蔵門ブログという企画をやっていた。通学などで東京メトロ半蔵門線(錦糸町~渋谷)に乗っている約30分だけを使って、noteで日記を書く。
最初は冗談半分でやっていた習慣だが、結局面白いように続いた。時間感覚が崩壊していてスケジューリングがめちゃくちゃ苦手な自分でも、よく使う電車なら時間ではなく駅名で時間経過を把握できたからかもしれない。時間もちょうどよかった。中央線だと長すぎるし、神戸電鉄神戸高速線だと短すぎる。(日本一短い路線らしいです)
渋谷に着いた時点で未完成でも無理やり投稿、一歩でも電車を降りれば誤字があっても修正は許されないというルールでやっていた。文章の読みやすさとか面白さとか、そういうのにこだわっているとあっという間に時間切れになるので、ハードルが低く気軽に書けた。地下鉄を使わなくなることは、これがなくなることを意味する。良くない。
良くないので、半蔵門線(錦糸町~渋谷)をいつでもどこでも再現できる良いWebページを作ろうと思う。そうすれば、良くなる。
手順
①半蔵門線の各駅間の所要時間を入手する
②そういうタイマーを作る
以上。わざわざ手順書く必要なかったな。
半蔵門線各駅の所要時間
調べると、東京メトロAPIというものがあった。電車の駅間の所要時間や乗降車数、さらに特定の車両がいまどこにいるのかまで分かる優れものらしい。
が、APIを利用するにはユーザー登録とログインが必要だった。審査に2営業日かかるらしいし、どうせ半蔵門線のデータしか使わないのでこのAPIは使わないことにした。どうにか人力で駅間の所要時間のデータを集めなければいけない。大変だ…。
 !
!
ぜんぜん大変じゃなかった。「メトロのトリセツ」というpdfブックがあって、そこにメトロ全線の所要時間が掲載されている。ひょっとして東京メトロは神なのか?
よく見てみると、渋谷から錦糸町までが29分。「約30分」という僕の直感は正しかった。そしてこの時間は、ポモドーロテクニックで推奨されている作業時間の25分ともだいたい同じだ!作業用タイマーとしての半蔵門線の有用性が証明されたことになる。少し背中を押された気分だ。頑張って作るぞ。
作る
スマホアプリやPCのソフトにするのは大変なので、簡単そうなHTMLとjavascriptの組み合わせでタイマーを作ってみる。
得られる情報は地下鉄車内にいるときと揃えたいので、
- 今どの駅にいるか
- 次の駅名
の2つを表示できるようにしたい。タイマーだが、残り時間は表示しない。地下鉄に乗っているときに頼りになるのは駅名表示だけなのだ。
というわけで、作った。
 普通のタイマーと処理はたいして変わっていないが、時刻の代わりに今いる駅名と次の駅名を表示している。
普通のタイマーと処理はたいして変わっていないが、時刻の代わりに今いる駅名と次の駅名を表示している。
``````javascript
function departure(direction){
startTime = new Date();
//各駅ごとに到達すべき時刻(時刻表)を作成する
stationID = 0;
var stationLen = stationList[direction].length
var diagramArray = [];
var stationName;
for (var i=0; i<stationLen; i++){
var stationName = stationList[direction][i][0];
stationMinute = stationList[direction][i][1];
var targetTime = new Date(startTime.getTime()+601000stationMinute);
diagramArray.push([stationName,targetTime])
console.log(stationName,targetTime)
}
finishTime = new Date(startTime.getTime()+601000stationList[direction][stationLen-1][1]);
//1秒ごとに処理をする
timerID = setInterval(function(){gatangoton(diagramArray)},1000);
}
function start(){
var direction;
if(document.getElementById("toggle").checked){
direction = 1
}else{
direction = 0
}
departure(direction)
} function gatangoton(diagramArray){
//1秒ごとに駅についたか判定する関数
var stationLen = diagramArray.length
var stationName = diagramArray[stationLen-1][0]
var curTime = new Date();
if (nextStationID == stationLen){
nextStationID = 0
}
var nextTime = diagramArray[nextStationID][1]
if (curTime.getTime() >= finishTime.getTime()){
//終点についたらタイマーを終える
finalArrival(stationName)
clearInterval()
}else if(curTime >= nextTime) {
nextStationID += 1;
curStationID += 1;
arrival(diagramArray,curStationID);
}
}
``````書いたコード
下のスイッチは、半蔵門線の進行方向を上り(渋谷方面)と下り(錦糸町方面)から選べるようにしたもの。正直どっちが上りでどっちが下りかは知らない。
いま調べたら、東京メトロは都心部を走っているために上りと下りの区別がないらしい。へ~~。
できた
というわけで、ちょっと綺麗にしてみた。

いい感じ。PCの全画面だと表示がぶっ壊れるバグに泣かされたが、それなりに見栄えがする。
電車のドアの開閉の音も流そうと思ったが、詳しい人に怒られそうな効果音と合法かわからない効果音の2択だったのでやめた。ノイキャンのイヤホンをつけているものとして、画面をチラチラ見ることで現在地を把握していきたい。
https://hanzomontimer.web.app/ のリンクから使えるので、みんなも半蔵門線に乗ったつもりになってほしい。僕の利用経路の都合上、渋谷と錦糸町しか出発地を選べないけど許して。
僕はしばらく、このタイマーを起動して到着するまでしっかり作業し、到着したら休憩するという仕組みで勉強や作業をしてみようと思う。もしこれで作業がはかどれば、作業用タイマーとしての半蔵門線の優位性が示されたことになるので東京メトロから褒めてもらえるかもしれない。
とりあえず今日は寝て、明日からちゃんと使ってみようと思います。
